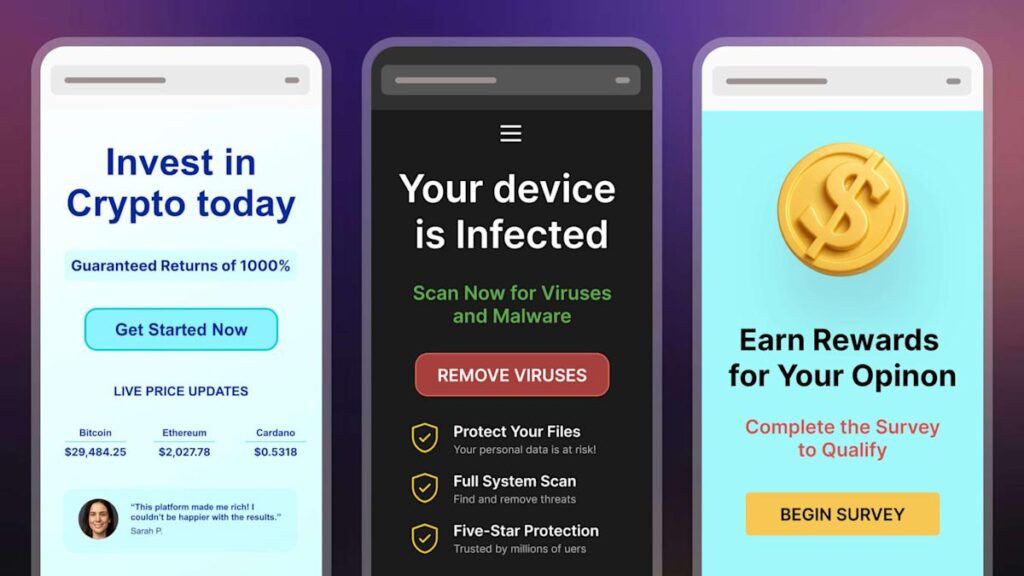
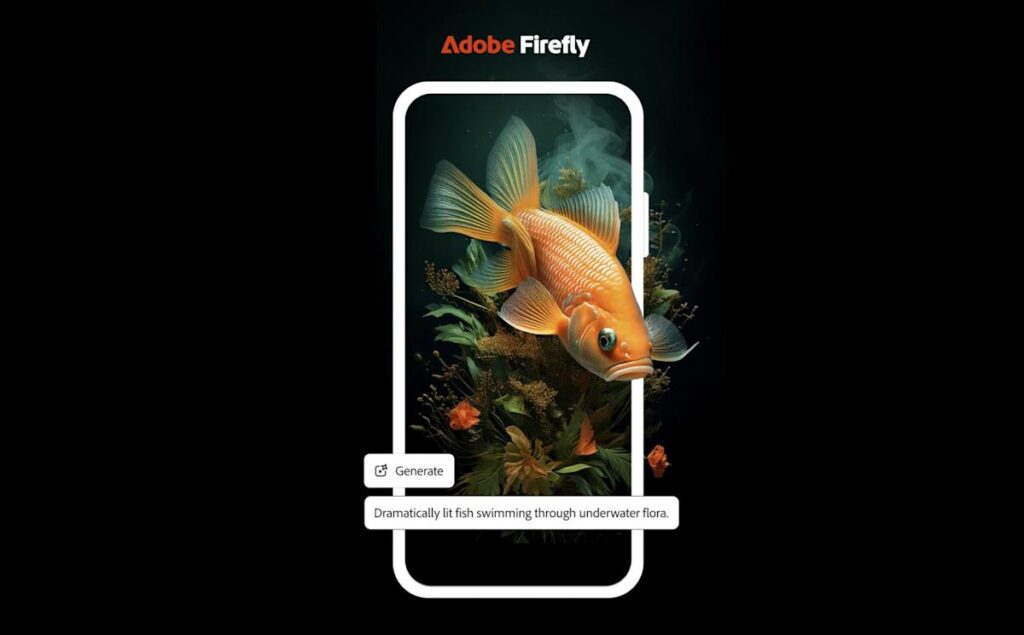
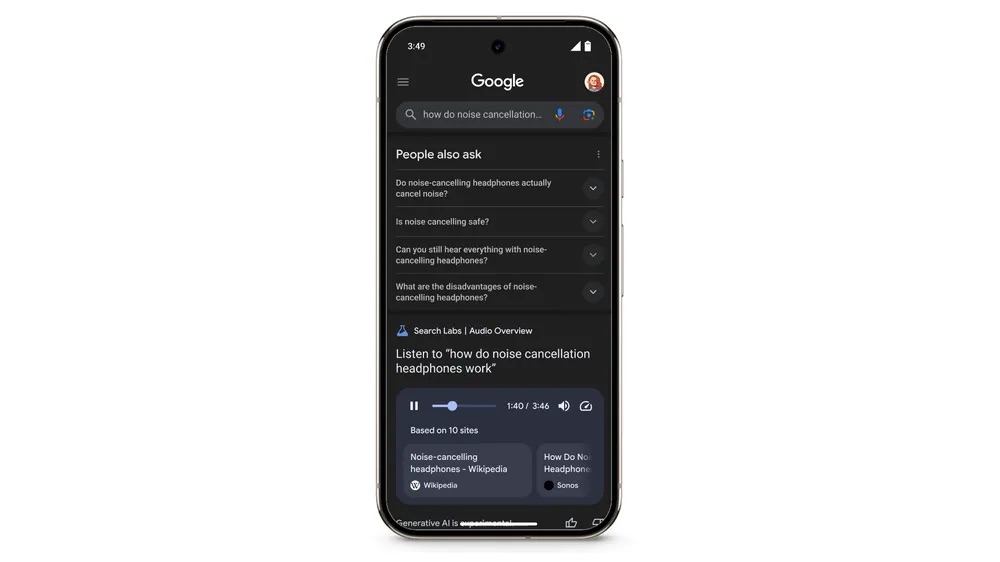
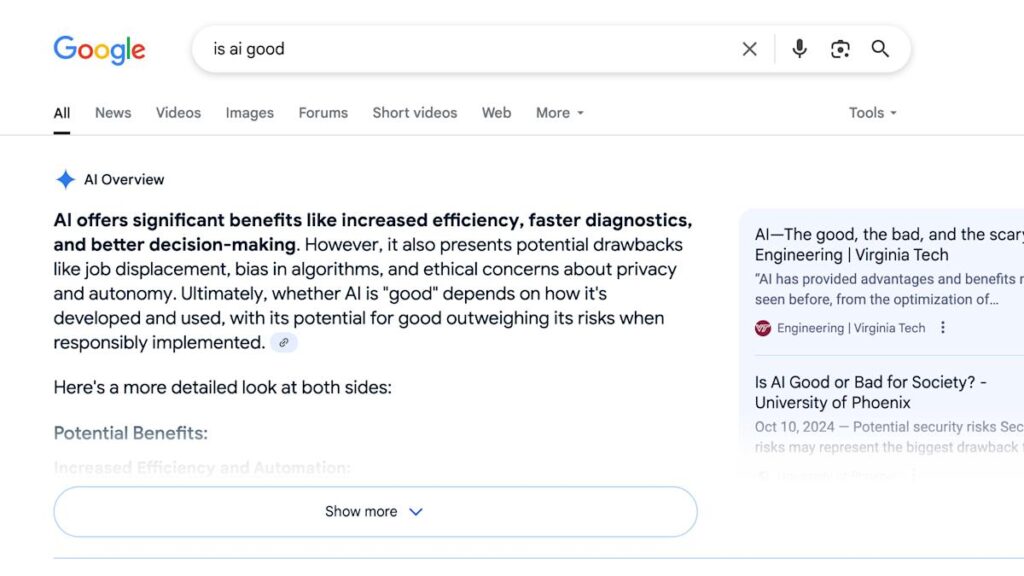
2025-06-22 Yapay Zeka Haber Özetleri
No: 1Kaynak: EngadgetBaşlık: Apple, Perplexity AI’ın Satın Alınmasını Gözden Geçiriyor.Link:https://www.engadget.com/ai/apple-is-reportedly-considering-the-acquisition-of-perplexity-ai-150012746.html?src=rssÖzet: Apple, Perplexity AI’ın satın alınmasını araştırmayı sürdürüyor ve yapay zeka […]